慢查询基础:优化数据访问
是否请求了不需要的数据
-
查询了不需要的记录,比如取条数要加上 limit ,不然MySQL会返回所有数据,然后丢弃绝大部分数据
-
多表关联时只返回需要的列,而不是所有表的所有列
-
任何时候都不要
select *除非系统做了缓存 -
不要重复查询相同的数据,如果发现需要查询相同的数据,那么最好用缓存
是否存在扫描额外的记录
响应时间
响应时间 = 服务器时间 + 排队时间
-
服务器时间:指数据库处理这个查询真正花了多长时间
-
排队时间:服务器因为等待某些资源而没有真正执行查询的时间,一般是 I/O 和锁等待,实际情况很复杂
扫描的行数和返回的行数
理想情况下,扫描的行数和返回的行数应该是相同的,不过这个基本上不可能,一般在 1:1 到 10:1 之间
扫描的行数和访问类型
根据主键 ID 查询
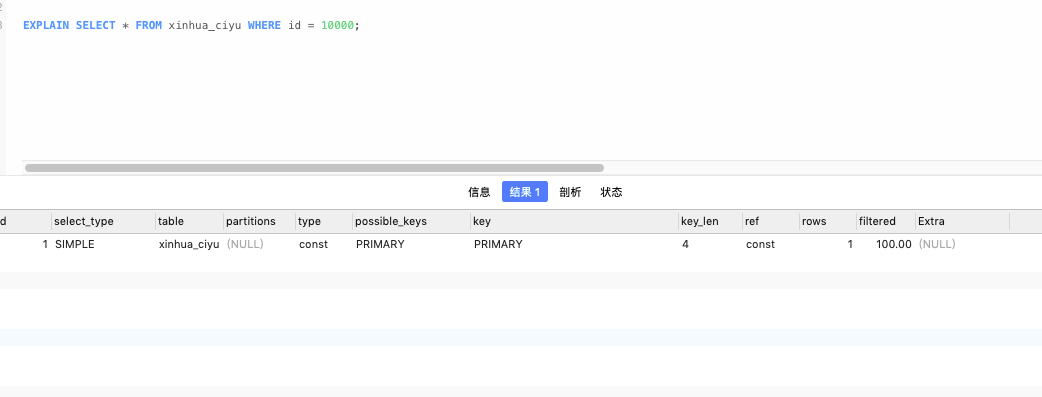
字段 ciyu 有唯一索引时:和主键ID基本一致
字段 ciyu 无索引时:如下图
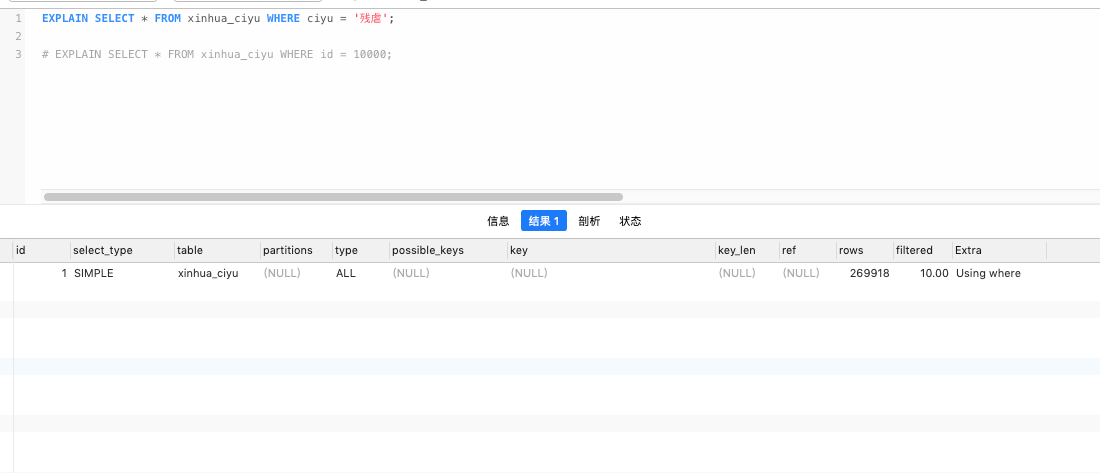
关于 EXPLAIN 各字段的解释,请看单独章
重构查询的方式
一个复杂查询还是多个简单查询
切分查询
将一个大查询分解成多个小查询
比如定期删除数据,如果一次性删除所有行,那么会锁住很多数据,占满事务日志,耗尽系统资源,阻塞很多小的但很重要的查询
每次删除一万条,每次删除后暂停一会再执行下一次删除,可以将服务器上原本一次性的压力分散到一个很长的时间内
delete from messages where created_at < DATE_SUB(NOW(),INTERVAL 3 MONTH);
# 可以拆分为
rows_affected = 0
do {
rows_affected = do_query (
"delete from messages where created_at < DATE_SUB(NOW(),INTERVAL 3 MONTH) limit 10000"
)
} while rows_affected > 0
分解关联查询
select * from tag
join tag_post on tag_post.tag_id = tag.id
join post on tag_post.post_id = post.id
where tag_tag = 'mysql';
# 可以分解成
select * from tag where tag = 'mysql';
select * from tag_post where tag_id = 1234;
select * from post where post.id in (123,345,456,9089,8904);
优势在哪里:
-
让缓存的效率更高,可以很方便的缓存单表查询对应的结果对象。例如,tag已经被缓存了,那么可以直接跳过第一个查询,如果缓存了 ID 为 123、 345、 456 的数据,那么第三个 IN 语句就可以少几个ID,还有 MySQL 的查询缓存来说,如果关联中的某个表发生了变化,那么就无法使用查询缓存了,而拆分之后,如果某个表的变化很小,那么基于该表的查询就可以重复利用查询缓存的结果了。
-
将查询分解后,执行单个查询可以减少锁的竞争
-
在应用层做关联,可以很方便的对数据库进行拆分,更容易做到高性能和可扩展
-
查询本身效率可能会有所提高,在这个例子中,使用 IN 代替关联查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的关联要更高效
-
可以减少冗余记录的查询。在应用层做关联查询,意味着对于某条记录,应用只需要查询一次,而在数据库中做关联查询,则可能需要重复地访问一部分数据,这样的重构还可能会减少网络和内存的消耗
-
更进一步,这样做相当于在应用层实现了哈希关联,而不是使用 MySQL 的嵌套循环关联,某些场景哈希关联的效率要高很多
MySQL 查询执行路径
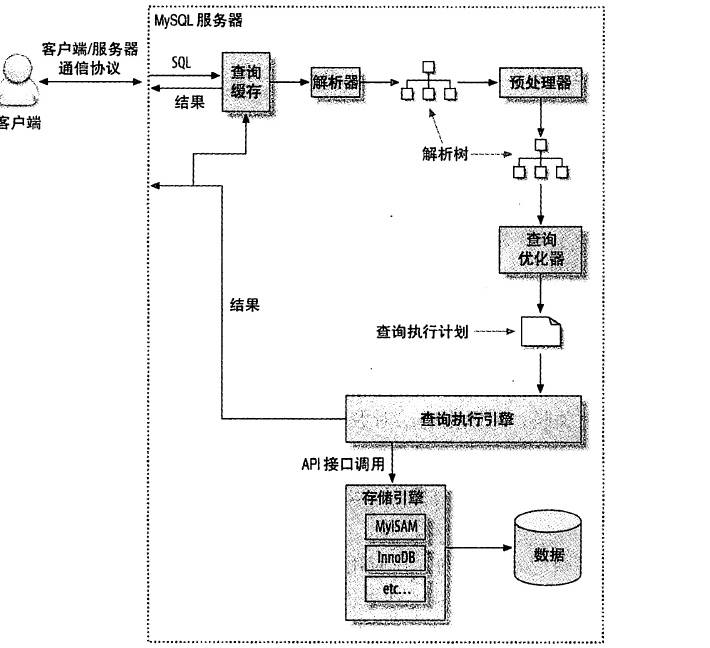
- 客户端发送一条查询给服务器
- 服务器先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API执行查询。
- 返回结果给客户端。
开启慢查询日志
临时开启(永久开启修改配置文件)
# 开启
set global slow_query_log = on;
# 关闭
set global slow_query_log = off;
设置慢查询时间
# 超过 1 秒的 SQL 都将被记录
set long_query_time = 1;
慢查询日志分析工具
##pt-query-digest
附录:一些配置
| 键 | 值 | 含义 |
|---|---|---|
| binlog_rows_query_log_events | OFF | 含义 |
| ft_query_expansion_limit | 20 | 含义 |
| have_query_cache | YES | 含义 |
| log_queries_not_using_indexes | OFF | 含义 |
| log_throttle_queries_not_using_indexes | 0 | 如果值设置为ON,则会记录所有没有利用索引的查询(性能优化时开启此项,平时不要开启) |
| long_query_time | 10.000000 | 超过多少秒的查询就写入日志 |
| query_alloc_block_size | 8192 | 含义 |
| query_cache_limit | 1048576 | 含义 |
| query_cache_min_res_unit | 4096 | 含义 |
| query_cache_size | 1048576 | 含义 |
| query_cache_type | OFF | 含义 |
| query_cache_wlock_invalidate | OFF | 含义 |
| query_prealloc_size | 8192 | 含义 |
| slow_query_log | OFF | 是否已经开启慢查询 |
| slow_query_log_file | /var/lib/mysql/iz2gwm4t76xtk4z-slow.log | 慢查询日志文件路径 |
| log_output | FILE | 慢查询日志存储方式,可为 table(保存在mysql库下的slow_log表中) |