啥是索引
索引是一个排好序的列表,在这个列表中存储着索引的值和包含这个值的数据所在行的物理地址

注:在MySQL中,索引是在
存储引擎层而不是服务器层实现的。这意味着我们所讨论的索引准确地说是InnoDB引擎或MyISAM引擎或其他存储引擎所实现的。
将随机 I/O 变为顺序 I/O
局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用程序运行期间所需要的数据通常比较集中由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此就具有局部性的程序而言,磁盘预读可以提高 I/O 效率。
磁盘预读要求每次都会预读的长度一般为页的整数倍。而且数据库系统将一个例程的大小设置等于一个页面,这样每个字节只需要一次 I/O 就可以完全加载。这里的页是通过页式的内存管理所实现的,概念在这里简单提一嘴。
分页机制:就是把内存地址空间分成几个很小的固定大小的页面,每一页的大小由内存决定。这些是为了从虚拟地址映射到物理地址,提高了内存和磁盘的利用率。
实现原理
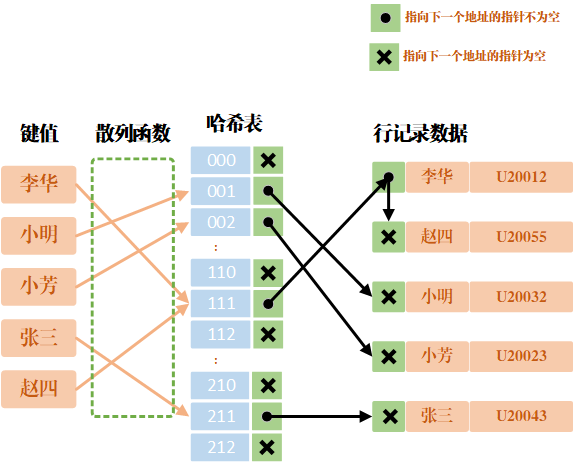
哈希索引
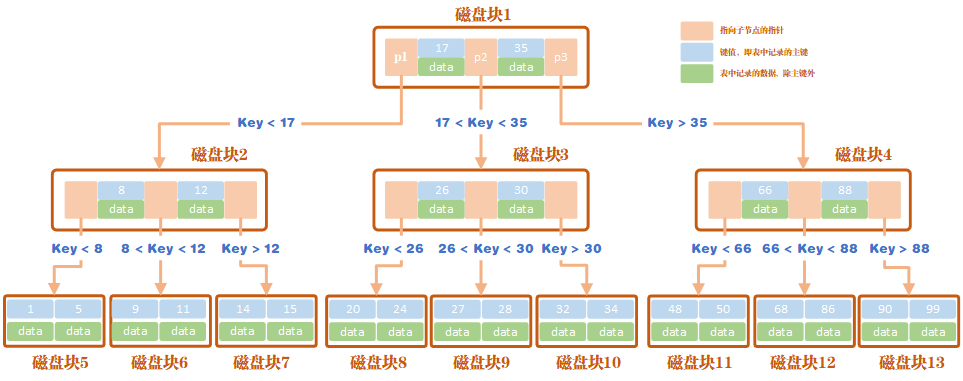
B 树索引
B+ 树索引


物理存储
聚簇索引
聚簇索引的主键索引的叶子结点存储的是键值对应的数据本身;辅助索引的叶子结点存储的是键值对应的数据的主键键值。
引用百度百科:聚簇索引也叫簇类索引,是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。由于聚簇索引的索引页面指针指向数据页面,所以使用聚簇索引查找数据几乎总是比使用非聚簇索引快。每张表只能建一个聚簇索引,并且建聚簇索引需要至少相当该表120%的附加空间,以存放该表的副本和索引中间页。
-
主键索引存储方式:
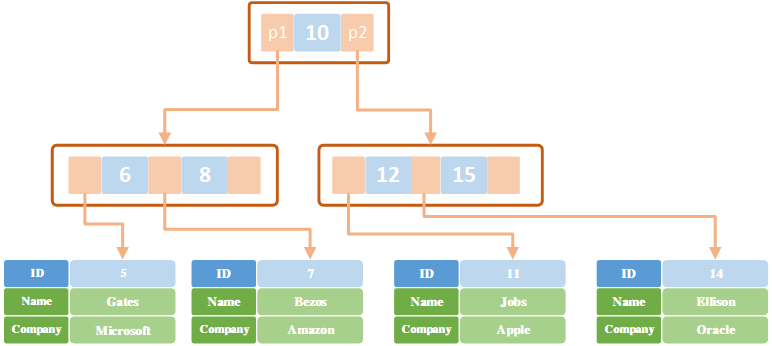
-
对应的辅助索引为:(键名称,大概的意思):
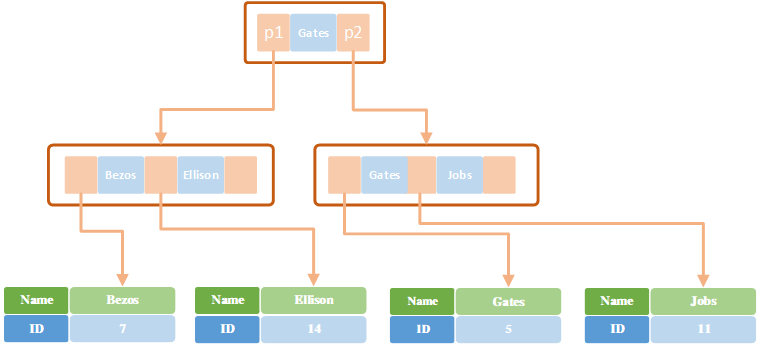
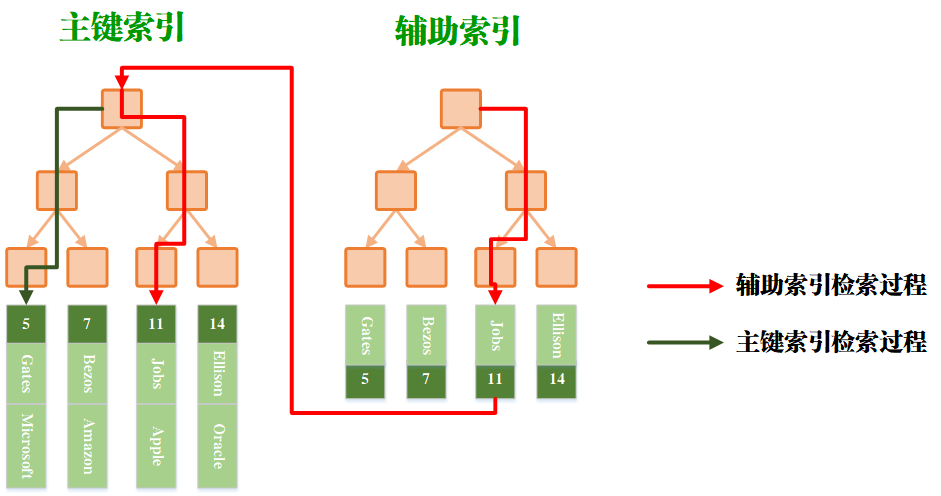
- 主键索引和辅助索引检索过程
非聚簇索引
非聚簇索引的主键索引和辅助索引几乎是一样的,只是主索引重复重复,替换空值,他们的叶子结点都存储指向键值对应的数据的物理地址。
百度百科:非聚簇索引,索引的一种。索引分为聚簇索引和非聚簇索引两种。建立索引的目的是加快对表中记录的查找或排序。索引顺序与数据物理排列顺序无关。 非聚簇索引,叶级页指向表中的记录,记录的物理顺序与逻辑顺序没有必然的联系。非聚簇索引则更像书的标准索引表,索引表中的顺序通常与实际的页码顺序是不一致的。
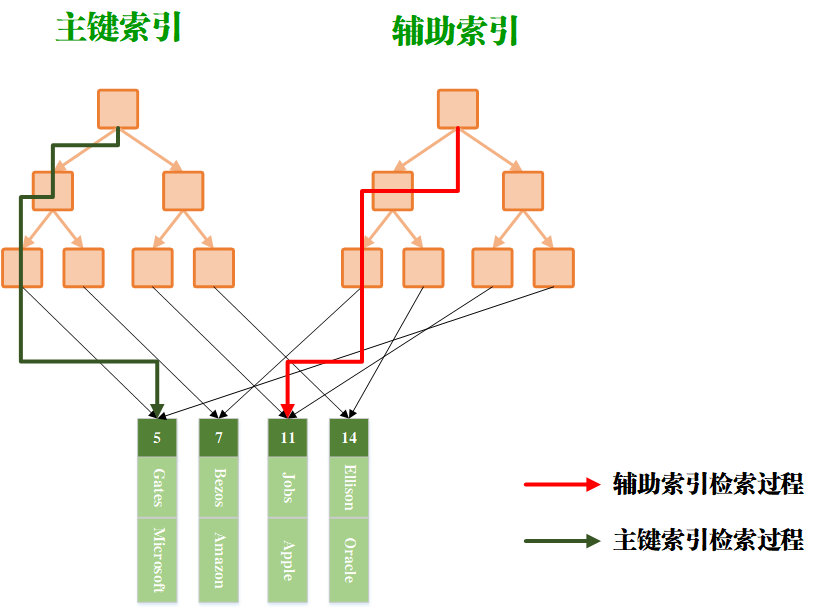
首先,主键索引和辅助索引的叶子结点都存储着键值对应的数据的物理地址,这说明无论是主键索引还是辅助索引都能够通过直接获得数据,而不需要像聚簇索引那样在检索辅助索引时还可以绕过一圈。
同时还说明一个点,叶子结点存储的是物理地址,那么表示数据实际上是存在另一个地方的,并不是存储在B +树的结点中。这说明非聚簇索引的数据表和索引表是分开存储的。
- 非聚簇索引的检索过程
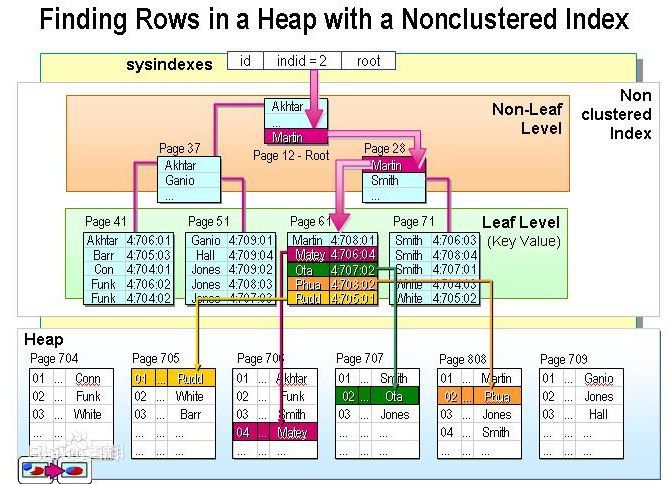
参考链接
- 参考一:https://maimai.cn/article/detail?fid=1499109222&efid=-mFwaUK5_mEKnkKdlaoZ5A&use_rn=1